BETA
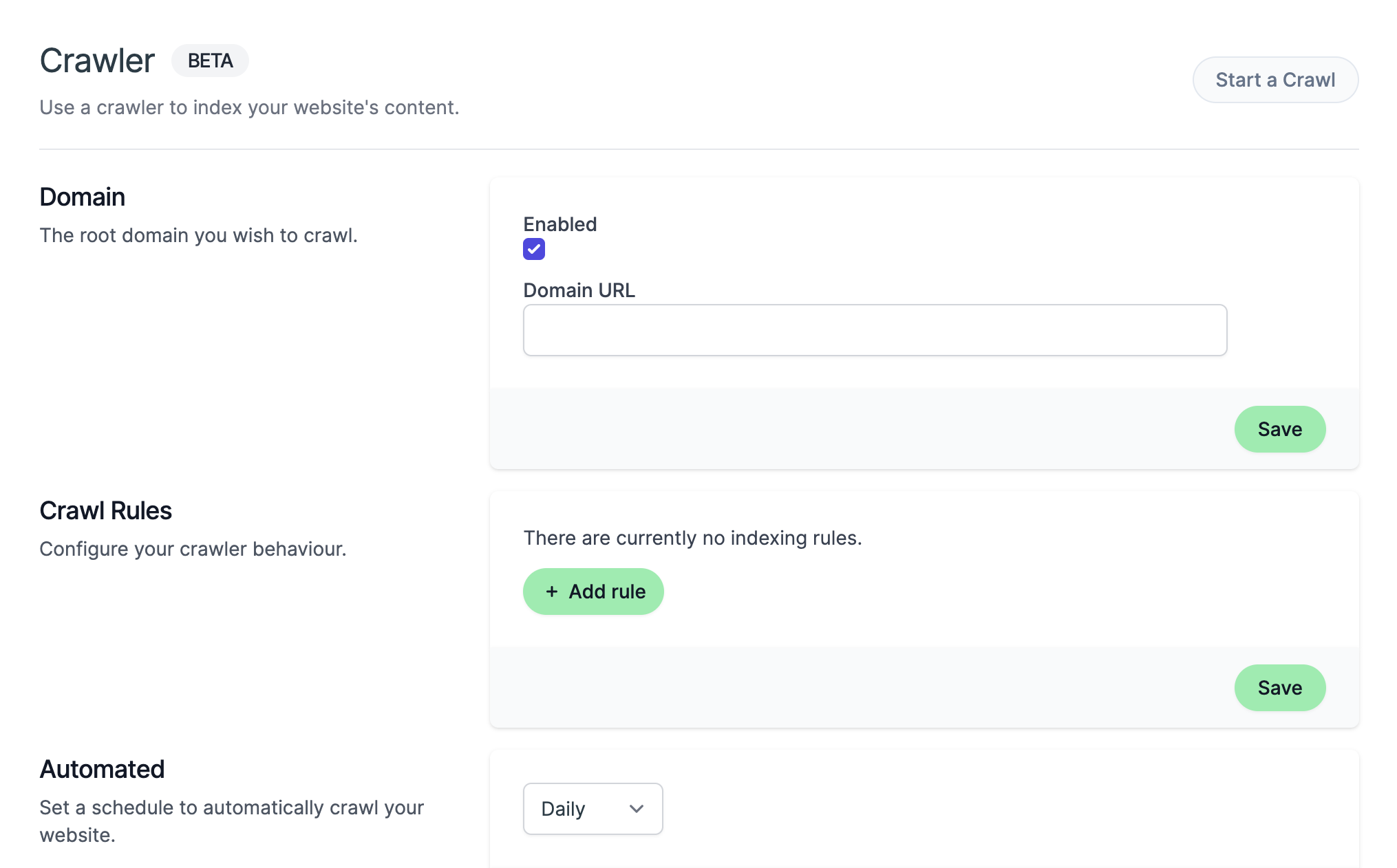
Web Crawler
Crawl your website content on an automated schedule. We store the pages for search and update them when the content changes.
Automated
Ingest web content
- Set a domain
- The url to be crawled to populate an index. Start the crawl at the root for a full index, or a sub route for a partial index.
- Configure crawl rules
- Ignore content to be crawled based on path. Set multiple rules for a crawler.
- Set a schedule
- You can manually invoke your crawler or set an automated daily or weekly schedule.